
Data Architecture for Mission Critical Systems
Published:
In environments where software is mission critical, it is important to choose the correct Data Architecture. In this post I’d like to explain a few considerations which should be taken into account when defining your data architecture.
1. (Temporarily) save all (log)data
When releasing a mission critical system in a production environment, make sure to save all system specific (log)data for at least a limited period of time. This allows 2nd or 3rd line IT support to analyze the data and investigate the cause of anomalies. The retention period of this data can be limited but should at least equal the maximum incident expected response time. 2nd/3rd line support should have easy access to these logs.
2. Set up your Data Warehouse or Data Lake
As your application landscape scales up, the amount of data you’ll be generating and processing will grow significantly. At one point in time you will need a central location to store all your data. This ‘location’ is what we call either a Data Warehouse or Data Lake, or a combination of both 😉. The definitions:
Data Warehouse A central repository of information that can be analyzed to make more informed decisions. Data flows into a data warehouse from transactional systems, relational databases, and other sources, typically on a regular cadence. Business analysts, data engineers, data scientists, and decision makers access the data through business intelligence (BI) tools, SQL clients, and other analytics applications. Source
Data Lake A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions. Source
Both serve their own purpose. The choice between either Data Warehouse or Data Lake implementation depends on the application landscape and the requirements of the stakeholders. If your applications are coming from a wide range of suppliers, it’s very likely that the generated logdata is structured in different ways. If you want to store all data in a central data warehouse, you would need to transform the logdata into the defined structure of the Data Warehouse. This can be both complex and costly. A Data Lake offers more flexibility in the sense that each application can store data in it’s native format.
| Data Lake | Data Warehouse | |
|---|---|---|
| Data Structure | Structured, Semi-Structured or Unstructured | Structured and Processed |
| Scheme | Native. Depends on source data | Pre-defined. Requires transformation from native data to defined structure |
| Data Processing | ELT (Extract, Load, Transform) | ETL (Extract, Transform, Load) |
| Accessibility | Still requires transformation to analyze and combine different data sources | Easy for users to query data and combine it with different sources |
2.1. Traditional Data Warehouse
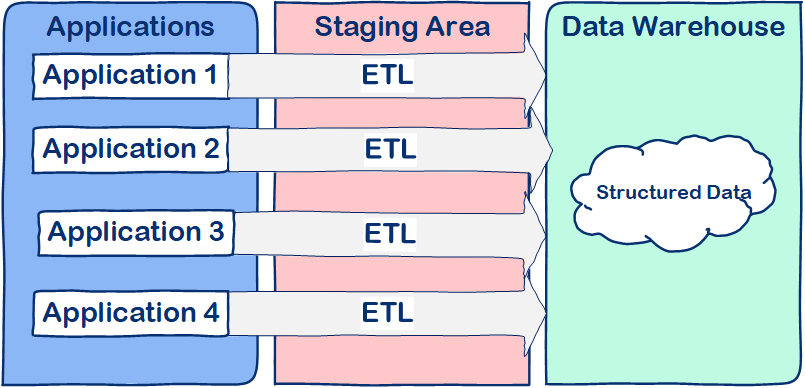 Figure 1: Traditional Data Warehouse architecture
Figure 1: Traditional Data Warehouse architecture
A traditional Data Warehouse Architecture is illustrated in Figure 1. All data coming from our applications must be Extracted from the source, Transformed to the database scheme, and then Loaded into the Data Warehouse. In that exact order. (ETL)
| Pros | Cons |
|---|---|
| Data is available in a structured format | Complex and costly to implement |
| Data from different sources can easily be combined | Not very flexible. Significant effort needed to add new sources |
2.2. Data Lake
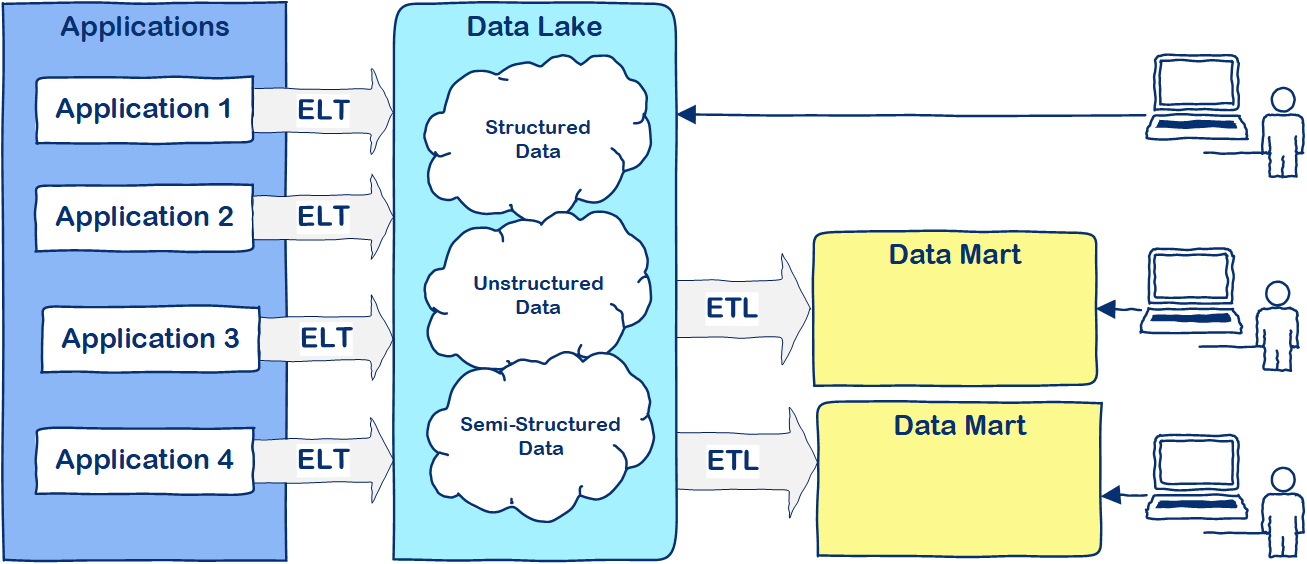 Figure 2: Data Lake Architecture
Figure 2: Data Lake Architecture
Figure 2 illustrates a Data Lake Architecture. Data is Extracted and afterwards Loaded into the Data Lake. The data is stored in it’s native format. In order to combine data from the Data Lake with other sources you would still need to Transform the data. (ELT)
| Pros | Cons |
|---|---|
| Very flexible. Easy to add new data sources | Requires additional transformation to combine with other sources |
| Easy to set up | Prone to inadequate governance and data security. Risk of becoming a ‘Swamp’ of data |
2.3. Converged Data Lake and Data Warehouse architecture
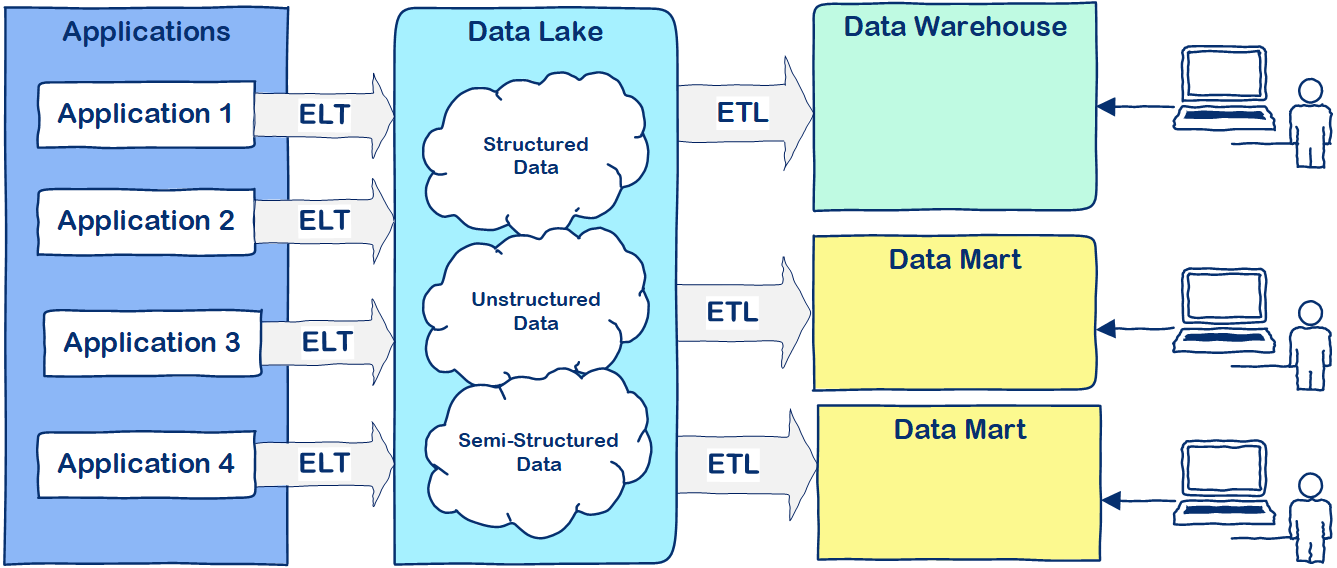 Figure 3: Converged Data Lake and Data Warehouse Architecture
Figure 3: Converged Data Lake and Data Warehouse Architecture
Figure 3 illustrates a convergence of Data Lake and Data Warehouse architecture. In my perception, this forms a new and richer data architecture. In a converged Data Lake/Data Warehouse architecture, the data is initially Extracted and Loaded into the Data Lake, all in native format. With relatively little effort you now have a central repository for all your data. From there you can start cleaning, filtering and Transforming your data to build up the Data Warehouse or create databases around subject areas, also known as Data Marts.
Both the Pros and Cons from the Traditional Data Warehouse as Data Lake architecture are applicable.
3. Create Data Mart on single subjects or focus areas
Each stakeholder has their own requirements when it comes to insight in data. It’s best practice to create separate Data Marts for each stakeholder. This way the stakeholder can easily query the ‘limited’ data in it’s data mart and doesn’t need to query through the entire Data Warehouse or Data Lake.
4. Filter your logdata
Modern applications either have different logging levels and/or have an indication of ‘severity’ in their logging data. Depending on the requirements of the stakeholder, you want to define which events are actionable and useful. Make sure to save these events and filter out the rest of the events that are not useful or actionable.